大模型(LLMs)基础面
一、介绍大模型
大模型:一般指1亿以上参数的模型,但是这个标准一直在升级,目前万亿参数以上的模型也有了。
大语言模型(Large Language Model,LLM)是针对语言的大模型。
大模型后面跟的6B、13B等,这些一般指参数的个数,B是Billion/十亿的意思。
二、主流框架体系
大模型主要架构分为三种::prefix Decoder 系、causal Decoder 系、Encoder-Decoder。
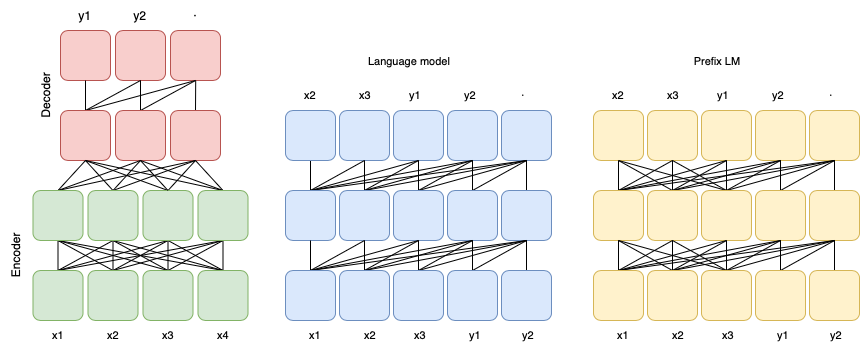
第一种:prefix Decoder系
- 介绍:输入双向注意力,输出单向注意力
- 定义:Prefix Decoder,也称为非因果解码器,属于Decoder only结构。输入部分使用双向注意力,输出部分使用单向注意力。在生成新的输出时,会考虑到所有之前生成的输出。
- 特点:Prefix Decoder在处理输入序列时,模型可以同时考虑序列中的所有词。生成输出时会考虑整个输入序列,而不仅仅是之前的输出。这使得它在处理需要全局上下文的任务时表现更好。训练阶段,通常使用自回归方式进行训练,即在生成当前词时,使用之前生成的所有词。Encoder和Decoder则共享了同一个Transformer结构,共享参数。
- 代表模型:ChatGLM、ChatGLM2、U-PaLM
第二种 :causal Decoder系
- 介绍:从左到右的单向注意力
- 定义:Causal Decoder,即因果解码器,属于Decoder only结构。输入和出均为单向注意力。在生成新的输出时,只会考虑到之前的输出,而不会考虑到未来的输出。
- 特点:与Prefix Decoder相比,Causal Decoder更注重序列的时序关系,因此在处理时间序列数据时具有优势。然而,在处理需要全局上下文的任务时,它可能不如Prefix Decoder表现得好。训练阶段,通常使用自回归方式进行训练,prefix Decoder 和 causal Decoder 主要的区别在于 attention mask不同。
- 代表模型:GPT系列、LLaMA-7B、BLOOM、LLaMa衍生物
第三种:Encoder-Decoder
- 介绍:输入双向注意力,输出单向注意力
- 定义:Encoder-Decoder包括一个编码器(Encoder)和一个解码器(Decoder)。编码器使用双向注意力,每个输入元素都可以关注到序列中的其他所有元素。解码器使用单向注意力,确保生成的每个词只能依赖于之前生成的词。编码器负责将输入数据转化为一个连续的向量,解码器则负责将这个向量转化为最终的输出。
- 特点:Encoder-Decoder结构能够将输入数据编码成一个固定维度的向量,然后通过解码器将这个向量解码成目标输出。这种结构能够有效地处理变长序列的转换问题,并且具有较强的通用性和灵活性。在训练时,Decoder的输入包括真实的前一个输出(teacher forcing策略)。和Prefix decoder不同,这里encoder和decoder参数独立。
- 代表模型:Transformer、T5、Flan-T5、BART
二、prefix Decoder 和 causal Decoder 和 Encoder-Decoder区别是什么?
prefix Decoder 和 causal Decoder 和 Encoder-Decoder 区别是在于 attention mask不同:
-
Encoder-Decoder:
- 在输入上采用双向注意力,对问题的编码理解更充分
- 适用任务:在偏理解的NLP任务上效果好
- 缺点:在长文本生成任务上效果差,训练效率低
-
causal Decoder:
- 自回归语义模型,预训练和下游应用是完全一致的,严格遵守 只有后面的token才能看到前面的token的规则
- 适用于任务:文本生成任务效果好
- 优点:训练效率高,zero-shot能力更强,具有涌现能力
-
prefix Decoder:
- 特点:prefix部分的token互相能看到 ,causal Decoder 和 Encoder-Decoder 折中
- 缺点:训练效率低
在下图中,灰色代表对应的两个token互相之间看不到,
蓝色:the attention between prefix tokens
绿色:the attention between prefix and target tokens
黄色:the attention betweetn target tokens and masked attention
例如,在Causal Decode里,”Survery”可以看到前面的“A”,但是看不到后面的“of”。
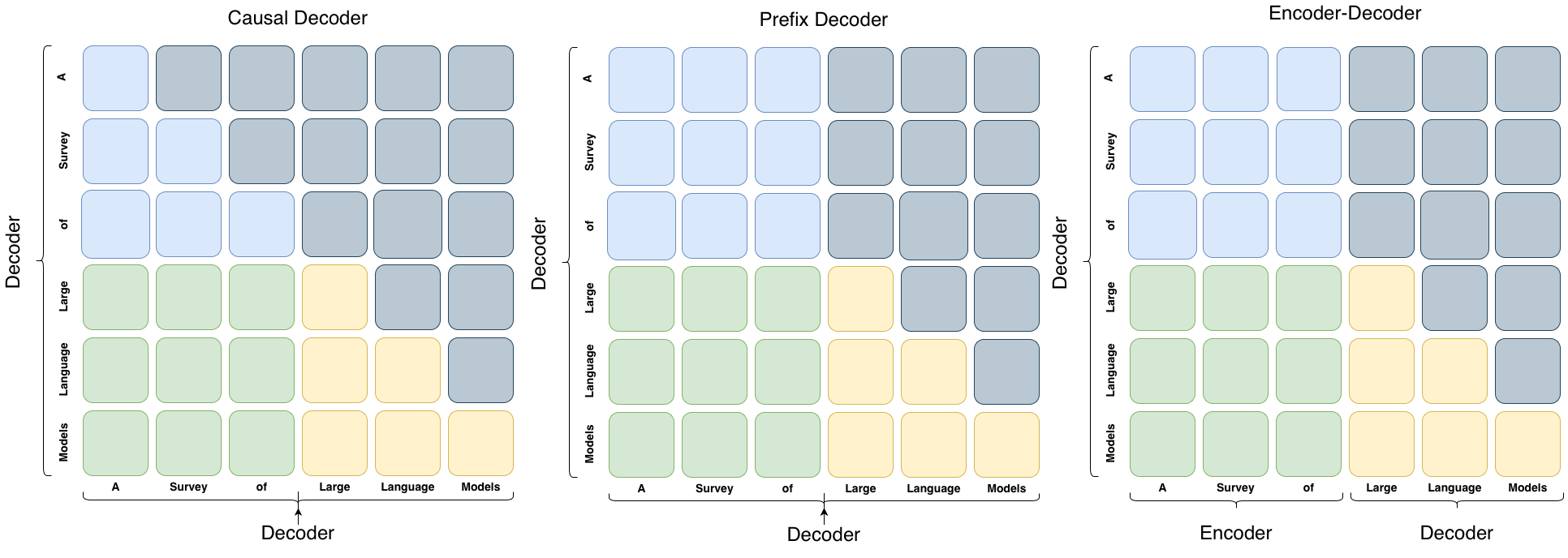
适用范围:
Prefix Decoder :适合那些需要理解全文上下文并基于此生成下文的任务。输入部分使用双向注意力,输出部分使用单向注意力。
Causal Decoder :适合那些需要生成文本并保证生成顺序符合因果关系的任务,如写故事或文章。无论是输入还是输出,都使用单向注意力。
Encoder-Decoder:适合那些需要理解完整输入序列并生成一个结构化输出的任务。编码器使用双向注意力,解码器使用单向注意力。
No Comments